

DNS (Domain Name System) is one of the most critical services at Hulu. Back in 2015, we published a blog post about our DNS infrastructure, which I highly recommend reading if you haven’t already. Since then, our DNS infrastructure has changed significantly to meet the features and scale of our growing organization.
How DNS Is Used at Hulu
IP addresses provide the remote resource locations that computers need to access in order to resolve websites like hulu.com. DNS (Domain Name System) was created to translate hostnames into usable IP addresses.
Here at Hulu, we have many services that communicate with each other using their DNS hostnames. Large organizations like Hulu need an internal DNS infrastructure that works reliably and at scale. In this article, we’ll look at how and why we arrived at our current DNS infrastructure.
Initially, we had eight DNS servers — split between our two primary data centers — to reply to queries. Machines in each data center had the IP address of these servers hardcoded into their configuration as the remote sources to query for DNS information.
In order to limit dependencies, we decided against using abstraction in the form of network load balancers. Instead, we chose to run Unbound as a local DNS cache on each machine.
The DNS servers themselves had a few different services running on them:
- Unbound (Running on port 53) — Initial layer that routes requests to another layer depending on the request.
- Unbound (Running on port 5301) — Answers queries for any externally hosted zones.
- PowerDNS (Running on port 5300) — Authoritative nameserver responsible for answering queries for any internally hosted zones.
Notably, our authoritative DNS for our externally-facing DNS is hosted by our CDN (content delivery network), and resolution of these DNS zones from our data centers is also routed to our CDN through the Unbound 5301 layer.
(For more detailed information, check out the previous blog post linked at the start of this post.)
This infrastructure worked very well for us at first, but as Hulu grew, its inherent limitations became more and more evident.
Issues Encountered
Limited Scalability
Because we put the IP addresses of the DNS servers directly into our configurations, we created a hard dependency on the individual DNS servers IP addresses. Over time, we eventually needed to retire specific DNS servers for various reasons and change their IP addresses.
Unfortunately, we realized that once we started using an IP address for DNS, it was almost impossible to completely retire. This is because we used DNS IP addresses in so many locations, and some of these — like network devices or storage appliances — were not easy to access and modify. As a result, we ended up maintaining many iterations of DNS servers, including retired servers that were still receiving queries from devices. Over time, maintaining these became more difficult.
Additionally, because we were not abstracting these IP addresses with a load balancer, our query throughput in a single data center was inherently limited by the number of queries our four DNS servers could handle. This was not a problem initially, but as we continued to grow, our throughput exceeded what our DNS servers could reliably handle.
Tedious Configuration Changes
Originally, we had the list of our internal domains hardcoded into our DNS servers’ unbound configuration files. This worked great — until we needed to add or change internal domain names for any reason. Doing so required that we make configuration changes to the DNS servers themselves. Because we were managing so many DNS servers — and had to coordinate and schedule update windows for each of them — this process was time-consuming and tedious.
Limited Flexibility
We also came across situations where we needed to perform more complex tasks with our DNS infrastructure, which was simply not feasible to do in its state.
For example, we needed an externally hosted domain (such as hulu.com) to resolve differently for external and internal requests. This was actually a pretty common scenario, but was not easy in the environment we’d set up.
In large part, this was because we routed requests for all externally hosted zones back out to our CDN provider. In order to accomplish this routing, we had to modify the configuration to route queries for that specific record to be served from our internal PowerDNS layer — as opposed to our Unbound 5301 layer — which was a tedious manual process.
Reintroducing Load Balancers: An Initial Attempt at Solving Scalability Issues
In order to tackle its scalability issues, we decided to reintroduce load balancers to our infrastructure by creating multiple DNS “clusters.”
Instead of putting all of our DNS servers behind a single load balancer, we put different clusters of DNS servers behind four different VIPs (virtual IPs) across a distributed software load balancer. The usage of four separate virtual IPs allowed us to scale our DNS infrastructure past the original four-server limitation and eliminate the dependency we had on the DNS server IP.
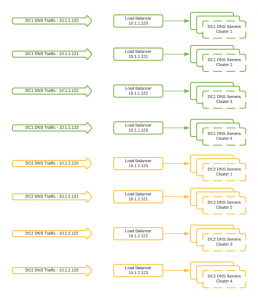
This design alleviated some of our scalability issues and was initially reliable. However, we eventually had an issue on our load balancing stack that caused all four of the DNS VIPs (in a single datacenter) to temporarily go offline.
We also continued to be limited in flexibility, and the number of DNS servers we were managing had grown in proportion to the number of servers we had behind our load balancers. Any necessary configuration changes now needed to be made on all the servers in the DNS clusters. (That said, it was much easier to retire those servers because we were no longer bound to their IP addresses.)
In the end, we realized that we needed to radically redesign our DNS architecture, both to solve the stability issues caused by our dependency on load balancers and to provide the increased flexibility and scalability that our growing organization needed.
Redesigning our DNS Infrastructure
Creation of a New Layer and Implementing Anycast DNS
In order to ensure scalability and decrease our dependence on external network devices, we realized we needed to build the functionality provided by load balancers into the DNS architecture.
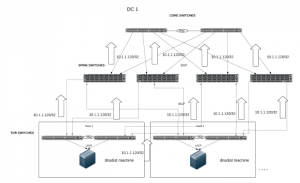
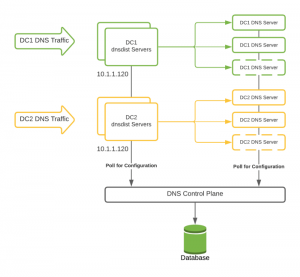
After evaluating a few options, we decided to create a new layer in our infrastructure that consisted of machines running dnsdist. Specifically tailored for DNS traffic, this new layer provided much more functionality than even our load balancers had. The dnsdist layer resided in each of our data centers, where it was the first hop for all of our DNS traffic. From there, it routed the DNS query to one of the available DNS servers actually serving the requests.
In collaboration with our networking team, we implemented a new method of routing DNS traffic to this layer using Anycast. The first layer (dnsdist) of our DNS infrastructure now ran a routing daemon, Quagga, to establish BGP sessions with their top of the rack switch and announce a single IP address (which was the same across our data centers). The rack switches then announced the IP address to our Spine Switches, which in turn announced the IP address to our Core Switches. Finally, the Core Switches announced the IP address to our Backbone Switches, where it would be announced and made available across our internal network.
Regardless of location, this IP address would be used as the DNS server for all of our infrastructure, and traffic would be routed to the closest server announcing that address via default route selection.
We also created a script to perform a local health check on each machine. The script was designed to resolve a record and then verify its expected output against its actual output. In the event that the health check failed, the script stopped the routing daemon, which in turn prevented the machine from receiving any further client requests.
As a result of these changes, all machines could use a single IP address for DNS, regardless of location. The new infrastructure completely eliminated our dependencies on load balancers, allowing us to continue scaling, and significantly simplified client configurations.
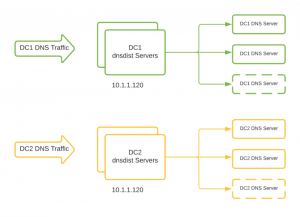
Creation of a new Control Plane for our DNS Infrastructure
Because we still needed a way to manage and configure the DNS (and dnsdist) servers, we created a new control plane specifically for our DNS infrastructure.
This control plane we created is a database-backed API containing all of our DNS servers, domains, and settings. Rather than specifying any settings (like the internal domains in configuration files on the DNS servers), we created a configuration daemon that runs on each of our servers in each layer of our DNS infrastructure.
Purpose of Configuration Daemon on dnsdist Servers
On our dnsdist servers, this daemon checks in with the control plane API in 30 second intervals. During the check-in process, the daemon grabs the configuration and updates its local configuration to match. This configuration generally includes the list of DNS server backends (local to the same datacenter) to which the dnsdist servers should route traffic.
Additionally, it also reports details of the instance and health back to the control plane allowing us to easily query a single source to see the dnsdist machines that are in use and receiving traffic.
Purpose of Configuration Daemon on DNS Servers
On our DNS servers, this daemon checks in with the control plane API in 30 second intervals.
During the check-in process, the daemon grabs the configuration from the control plane and dynamically updates its local configuration to match. This configuration generally includes the list of internal domains that should be routed to PowerDNS rather than being routed externally by default.
The configuration update itself is performed using unbound control, which allows us to modify the running Unbound configuration without needing to restart any services. Additionally, it reports health and instance details back to the control plane, allowing us to easily query a single source to identify the DNS servers that are in use and receiving traffic.
Changing Resolution of Externally Hosted Zones
In order to perform the complex routing that we wanted to support, we first needed to stop sending queries for our externally hosted zones back out to our CDN provider. We served them from our internal database of records instead, allowing us to have different records served internally for our externally hosted zones.
We were surprised to learn that this actually didn’t change much, as the records that were served by our CDN provider were already stored internally.
Making Mass Configuration Changes in Failure Scenarios
Since then, we have expanded on the control plane to support many more configurable options. These options allow us to perform different actions to machines in our DNS infrastructure, like remotely enabling or disabling nodes.
We have also been able to improve the availability and redundancy of our DNS infrastructure with this architecture, because it enables us to make mass configuration routing changes instantaneously. As a result, we can mitigate the impact of many different failure scenarios that may not be handled by the local health checks running on the servers themselves.
For example, in the event that outbound internet traffic is affected in one of our data centers, we can easily redirect DNS traffic for the entire data center to another data center by changing the backends that the dnsdist machines use in our control plane to that of another data center.

The new, dynamically configured Anycast DNS infrastructure we created has improved upon previous iterations of DNS at Hulu, providing more flexibility, redundancy, scalability and ease of use. The overall reliability of the service has increased; it now provides nearly 100% availability.
Our new DNS infrastructure is now handling all of our data center DNS traffic and we are excited about the possibilities that it provides.
If you’re interested in working on projects like these and powering play at Hulu, see our current job openings here.


